Week 11 [Oct 28]
- [W11.1] Design Patterns: Intermediate-Level
-
[W11.1a] Design → Design Patterns → MVC Pattern → What
-
[W11.1b] Design → Design Patterns → Observer Pattern → What
-
[W11.1c] Design → Design Patterns → Other Design Patterns
-
[W11.1d] Design → Design Patterns → Combining Design Patterns
-
[W11.1e] Design → Design Patterns → Using Design Patterns
-
[W11.1f] Design → Design Patterns → Design Patterns vs Design Principles
-
[W11.1g] Design → Design Patterns → Other Types of Patterns
- [W11.2] Combining Multiple Test Inputs
-
[W11.2a] Quality Assurance → Test Case Design → Combining Test Inputs → Why
-
[W11.2b] Quality Assurance → Test Case Design → Combining Test Inputs → Test Input Combination Strategies
-
[W11.2c] Quality Assurance → Test Case Design → Combining Test Inputs → Heuristic: Each Valid Input at Least Once in a Positive Test Case
-
[W11.2d] Quality Assurance → Test Case Design → Combining Test Inputs → Heuristic: No More Than One Invalid Input In A Test Case
-
[W11.2e] Quality Assurance → Test Case Design → Combining Test Inputs → Mix
- [W11.3] SDLC Process Models
-
[W11.3a] Project Management → SDLC Process Models → Introduction → What
-
[W11.3b] Project Management → SDLC Process Models → Introduction → Sequential Models
-
[W11.3c] Project Management → SDLC Process Models → Introduction → Iterative Models
-
[W11.3d] Project Management → SDLC Process Models → Introduction → Agile Models
-
[W11.3e] Project Management → SDLC Process Models → Scrum
-
[W11.3f] Project Management → SDLC Process Models → XP
-
[W11.3g] Project Management → SDLC Process Models → Unified Process
-
[W11.3h] Project Management → SDLC Process Models → CMMI
-
[W11.3i] Project Management → SDLC Process Models → Recap
W11.1a Design → Design Patterns → MVC Pattern → What
Can explain the Model View Controller (MVC) design pattern
Context
Most applications support storage/retrieval of information, displaying of information to the user (often via multiple UIs having different formats), and changing stored information based on external inputs.
Problem
The high coupling that can result from the interlinked nature of the features described above.
Solution
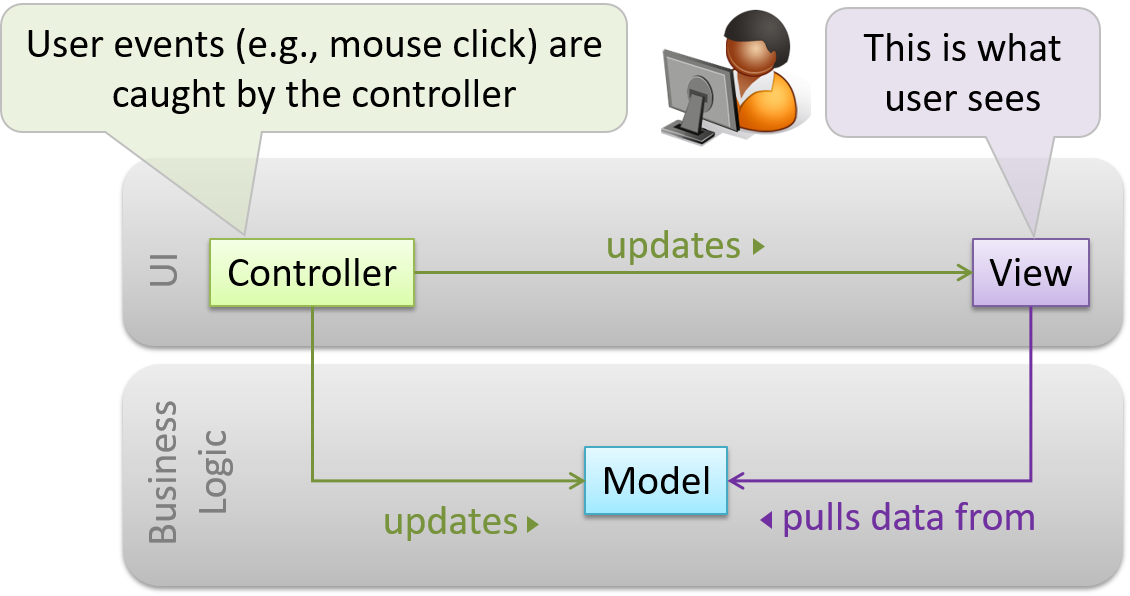
Decouple data, presentation, and control logic of an application by separating them into three different components: Model, View and Controller.
- View: Displays data, interacts with the user, and pulls data from the model if necessary.
- Controller: Detects UI events such as mouse clicks, button pushes and takes follow up action. Updates/changes the model/view when necessary.
- Model: Stores and maintains data. Updates views if necessary.
The relationship between the components can be observed in the diagram below. Typically, the UI is the combination of view and controller.
Given below is a concrete example of MVC applied to a student management system. In this scenario, the user is retrieving data of one student.
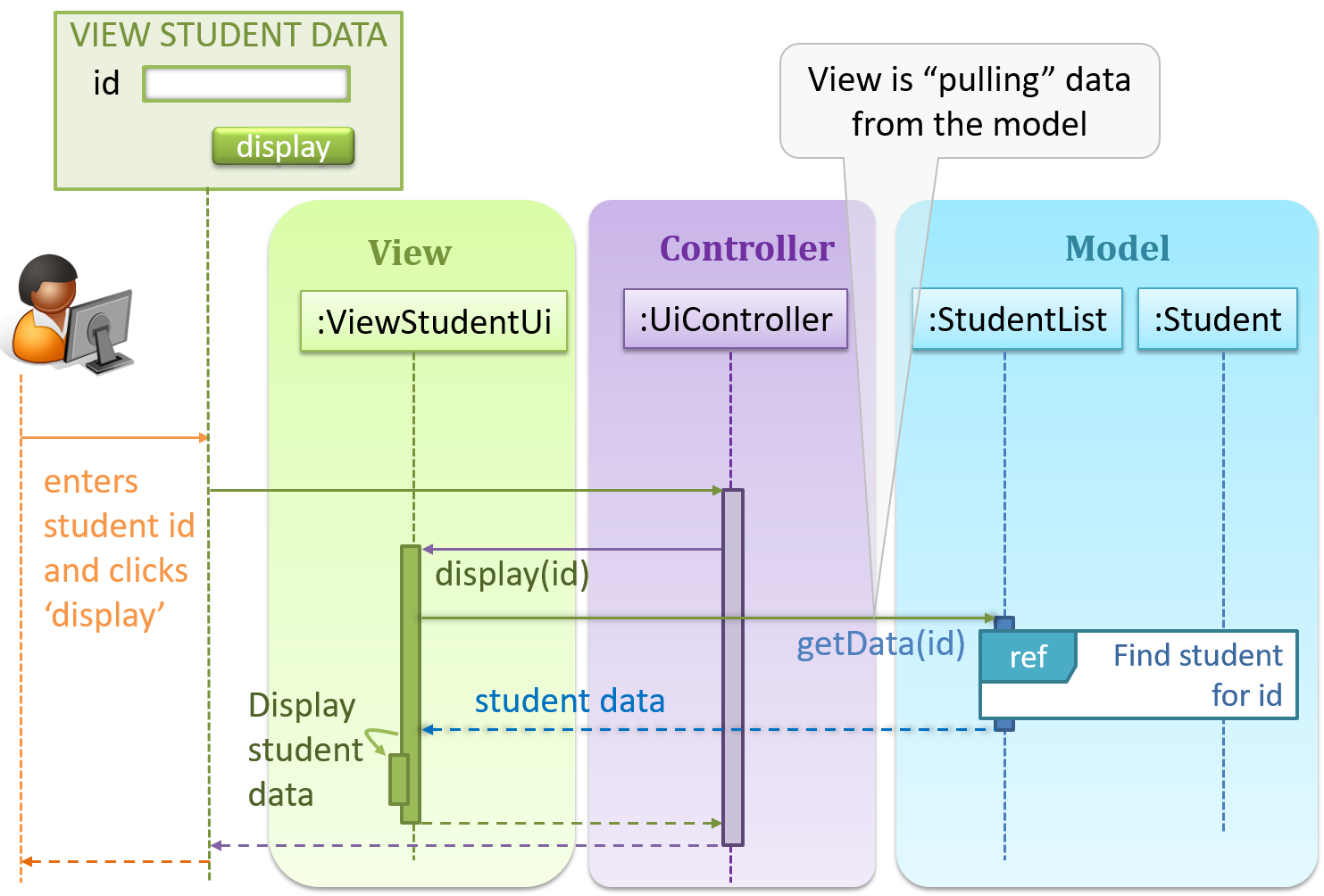
In the diagram above, when the user clicks on a button using the UI, the ‘click’ event is caught and handled by the UiController. The ref frame indicates that the interactions within that frame have been extracted out to another separate sequence diagram.
Note that in a simple UI where there’s only one view, Controller and View can be combined as one class.
There are many variations of the MVC model used in different domains. For example, the one used in a desktop GUI could be different from the one used in a Web application.
W11.1b Design → Design Patterns → Observer Pattern → What
Can explain the Observer design pattern
Context
An object (possibly, more than one) is interested to get notified when a change happens to another object. That is, some objects want to ‘observe’ another object.
Consider this scenario from the a student management system where the user is adding a new student to the system.

Now, assume the system has two additional views used in parallel by different users:
StudentListUi: that accesses a list of students andStudentStatsUi: that generates statistics of current students.
When a student is added to the database using NewStudentUi shown above, both StudentListUi and StudentStatsUi should get updated automatically, as shown below.

However, the StudentList object has no knowledge about StudentListUi and StudentStatsUi (note the direction of the navigability) and has no way to inform those objects. This is an example of the type of problem addressed by the Observer pattern.
Problem
The ‘observed’ object does not want to be coupled to objects that are ‘observing’ it.
Solution
Force the communication through an interface known to both parties.

Here is the Observer pattern applied to the student management system.
During the initialization of the system,
-
First, create the relevant objects.
StudentList studentList = new StudentList(); StudentListUi listUi = new StudentListUi(); StudentStatusUi statusUi = new StudentStatsUi(); -
Next, the two UIs indicate to the
StudentListthat they are interested in being updated wheneverStudentListchanges. This is also known as ‘subscribing for updates’.studentList.addUi(listUi); studentList.addUi(statusUi); -
Within the
addUioperation ofStudentList, all Observer objects subscribers are added to an internal data structure calledobserverList.//StudentList class public void addUi(Observer o) { observerList.add(o); }
Now, whenever the data in StudentList changes (e.g. when a new student is added to the StudentList),
-
All interested observers are updated by calling the
notifyUIsoperation.//StudentList class public void notifyUIs() { //for each observer in the list for(Observer o: observerList){ o.update(); } } -
UIs can then pull data from the
StudentListwhenever theupdateoperation is called.//StudentListUI class public void update() { //refresh UI by pulling data from StudentList }Note that
StudentListis unaware of the exact nature of the two UIs but still manages to communicate with them via an intermediary.
Here is the generic description of the observer pattern:

<<Observer>>is an interface: any class that implements it can observe an<<Observable>>. Any number of<<Observer>>objects can observe (i.e. listen to changes of) the<<Observable>>object.- The
<<Observable>>maintains a list of<<Observer>>objects.addObserver(Observer)operation adds a new<<Observer>>to the list of<<Observer>>s. - Whenever there is a change in the
<<Observable>>, thenotifyObservers()operation is called that will call theupdate()operation of all<<Observer>>sin the list.
In a GUI application, how is the Controller notified when the “save” button is clicked? UI frameworks such as JavaFX has inbuilt support for the Observer pattern.
Explain how polymorphism is used in the Observer pattern.

With respect to the general form of the Observer pattern given above, when the Observable object invokes the notifyObservers() method, it is treating all ConcreteObserver objects as a general type called Observer and calling the update() method of each of them. However, the update() method of each ConcreteObserver could potentially show different behavior based on its actual type. That is, update() method shows polymorphic behavior.
In the example given below, the notifyUIs operation can result in StudentListUi and StudentStatsUi changing their views in two different ways.

The Observer pattern can be used when we want one object to initiate an activity in another object without having a direct dependency from the first object to the second object.
True
Explanation: Yes. For example, when applying the Observer pattern to an MVC structure, Views can get notified and update themselves about a change to the Model without the Model having to depend on the Views.
W11.1c Design → Design Patterns → Other Design Patterns
Can recognize some of the GoF design patterns
The most famous source of design patterns is the "Gang of Four" (GoF) book which contains 23 design patterns divided into three categories:
- Creational: About object creation. They separate the operation of an application from how its objects are created.
- Abstract Factory, Builder, Factory Method, Prototype, Singleton
- Structural: About the composition of objects into larger structures while catering for future extension in structure.
- Adapter, Bridge, Composite, Decorator, Façade, Flyweight, Proxy
- Behavioral: Defining how objects interact and how responsibility is distributed among them.
- Chain of Responsibility, Command, Interpreter, Template Method, Iterator, Mediator, Memento, Observer, State, Strategy, Visitor
W11.1d Design → Design Patterns → Combining Design Patterns
Can combine multiple patterns to fit a context
Design patterns are usually embedded in a larger design and sometimes applied in combination with other design patterns.
Let us look at a case study that shows how design patterns are used in the design of a class structure for a Stock Inventory System (SIS) for a shop. The shop sells appliances, and accessories for the appliances. SIS simply stores information about each item in the store.
Use Cases:
- Create a new item
- View information about an item
- Modify information about an item
- View all available accessories for a given appliance
- List all items in the store
SIS can be accessed using multiple terminals. Shop assistants use their own terminals to access SIS, while the shop manager’s terminal continuously displays a list of all items in store. In the future, it is expected that suppliers of items use their own applications to connect to SIS to get real-time information about current stock status. User authentication is not required for the current version, but may be required in the future.
A step by step explanation of the design is given below. Note that this is one out of many possible designs. Design patterns are also applied where appropriate.
A StockItem can be an Appliance or an Accessory.

To track that each Accessory is associated with the correct Appliance, consider the following alternative class structures.

The third one seems more appropriate (the second one is suitable if accessories can have accessories). Next, consider between keeping a list of Appliances, and a list of StockItems. Which is more appropriate?

The latter seems more suitable because it can handle both appliances and accessories the same way. Next, an abstraction occurrence pattern is applied to keep track of StockItems.

Note the inclusion of navigabilities. Here’s a sample object diagram based on the class model created thus far.

Next, apply the façade pattern to shield the SIS internals from the UI.

As UI consists of multiple views, the MVC pattern is applied here.

Some views need to be updated when the data change; apply the Observer pattern here.

In addition, the Singleton pattern can be applied to the façade class.
W11.1e Design → Design Patterns → Using Design Patterns
Can explain pros and cons of design patterns
Design pattern provides a high-level vocabulary to talk about design.
Someone can say 'apply Observer pattern here' instead of having to describe the mechanics of the solution in detail.
Knowing more patterns is a way to become more ‘experienced’. Aim to learn at least the context and the problem of patterns so that when you encounter those problems you know where to look for a solution.
Some patterns are domain-specific e.g. patterns for distributed applications, some are created in-house e.g. patterns in the company/project and some can be self-created e.g. from past experience.
Be careful not to overuse patterns. Do not throw patterns at a problem at every opportunity. Patterns come with overhead such as adding more classes or increasing the levels of abstraction. Use them only when they are needed. Before applying a pattern, make sure that:
- there is substantial improvement in the design, not just superficial.
- the associated tradeoffs are carefully considered. There are times when a design pattern is not appropriate (or an overkill).
W11.1f Design → Design Patterns → Design Patterns vs Design Principles
Can differentiate between design patterns and principles
Design principles have varying degrees of formality – rules, opinions, rules of thumb, observations, and axioms. Compared to design patterns, principles are more general, have wider applicability, with correspondingly greater overlap among them.
W11.1g Design → Design Patterns → Other Types of Patterns
Can explain how patterns exist beyond software design domain
The notion of capturing design ideas as "patterns" is usually attributed to Christopher Alexander. He is a building architect noted for his theories about design. His book Timeless way of building talks about "design patterns" for constructing buildings.
Here is a sample pattern from that book:
When a room has a window with a view, the window becomes a focal point: people are attracted to the window and want to look through it. The furniture in the room creates a second focal point: everyone is attracted toward whatever point the furniture aims them at (usually the center of the room or a TV). This makes people feel uncomfortable. They want to look out the window, and toward the other focus at the same time. If you rearrange the furniture, so that its focal point becomes the window, then everyone will suddenly notice that the room is much more “comfortable”
Apparently, patterns and anti-patterns are found in the field of building architecture. This is because they are general concepts applicable to any domain, not just software design. In software engineering, there are many general types of patterns: Analysis patterns, Design patterns, Testing patterns, Architectural patterns, Project management patterns, and so on.
In fact, the abstraction occurrence pattern is more of an analysis pattern than a design pattern, while MVC is more of an architectural pattern.
New patterns can be created too. If a common problem needs to be solved frequently that leads to a non-obvious and better solution, it can be formulated as a pattern so that it can be reused by others. However, don’t reinvent the wheel; the pattern might already exist.
Here are some common elements of a design pattern: Name, Context, Problem, Solution, Anti-patterns (optional), Consequences (optional), other useful information (optional).
Using similar elements, describe a pattern that is not a design pattern. It must be a pattern you have noticed, not a pattern already documented by others. You may also give a pattern not related to software.
Some examples:
- A pattern for testing textual UIs.
- A pattern for striking a good bargain at a mall such as Sim-Lim Square.
W11.2a Quality Assurance → Test Case Design → Combining Test Inputs → Why
Can explain the need for strategies to combine test inputs
An SUT can take multiple inputs. You can select values for each input (using equivalence partitioning, boundary value analysis, or some other technique).
an SUT that takes multiple inputs and some values chosen as values for each input:
- Method to test:
calculateGrade(participation, projectGrade, isAbsent, examScore) - Values to test:
Input valid values to test invalid values to test participation 0, 1, 19, 20 21, 22 projectGrade A, B, C, D, F isAbsent true, false examScore 0, 1, 69, 70, 71, 72
Testing all possible combinations is effective but not efficient. If you test all possible combinations for the above example, you need to test 6x5x2x6=360 cases. Doing so has a higher chance of discovering bugs (i.e. effective) but the number of test cases can be too high (i.e. not efficient). Therefore, we need smarter ways to combine test inputs that are both effective and efficient.
W11.2b Quality Assurance → Test Case Design → Combining Test Inputs → Test Input Combination Strategies
Can explain some basic test input combination strategies
Given below are some basic strategies for generating a set of test cases by combining multiple test input combination strategies.
Let's assume the SUT has the following three inputs and you have selected the given values for testing:
SUT: foo(p1 char, p2 int, p3 boolean)
Values to test:
| Input | Values |
|---|---|
| p1 | a, b, c |
| p2 | 1, 2, 3 |
| p3 | T, F |
The all combinations strategy generates test cases for each unique combination of test inputs.
the strategy generates 3x3x2=18 test cases
| Test Case | p1 | p2 | p3 |
|---|---|---|---|
| 1 | a | 1 | T |
| 2 | a | 1 | F |
| 3 | a | 2 | T |
| ... | ... | ... | ... |
| 18 | c | 3 | F |
The at least once strategy includes each test input at least once.
this strategy generates 3 test cases.
| Test Case | p1 | p2 | p3 |
|---|---|---|---|
| 1 | a | 1 | T |
| 2 | b | 2 | F |
| 3 | c | 3 | VV/IV |
VV/IV = Any Valid Value / Any Invalid Value
The all pairs strategy creates test cases so that for any given pair of inputs, all combinations between them are tested. It is based on the observations that a bug is rarely the result of more than two interacting factors. The resulting number of test cases is lower than the all combinations strategy, but higher than the at least once approach.
this strategy generates 9 test cases:
Let's first consider inputs p1 and p2:
| Input | Values |
|---|---|
| p1 | a, b, c |
| p2 | 1, 2, 3 |
These values can generate
Next, let's consider p1 and p3.
| Input | Values |
|---|---|
| p1 | a, b, c |
| p3 | T, F |
These values can generate
Similarly, inputs p2 and p3 generates another 6 combinations.
The 9 test cases given below covers all those 9+6+6 combinations.
| Test Case | p1 | p2 | p3 |
|---|---|---|---|
| 1 | a | 1 | T |
| 2 | a | 2 | T |
| 3 | a | 3 | F |
| 4 | b | 1 | F |
| 5 | b | 2 | T |
| 6 | b | 3 | F |
| 7 | c | 1 | T |
| 8 | c | 2 | F |
| 9 | c | 3 | T |
A variation of this strategy is to test all pairs of inputs but only for inputs that could influence each other.
Testing all pairs between p1 and p3 only while ensuring all p3 values are tested at least once
| Test Case | p1 | p2 | p3 |
|---|---|---|---|
| 1 | a | 1 | T |
| 2 | a | 2 | F |
| 3 | b | 3 | T |
| 4 | b | VV/IV | F |
| 5 | c | VV/IV | T |
| 6 | c | VV/IV | F |
The random strategy generates test cases using one of the other strategies and then pick a subset randomly (presumably because the original set of test cases is too big).
There are other strategies that can be used too.
W11.2c Quality Assurance → Test Case Design → Combining Test Inputs → Heuristic: Each Valid Input at Least Once in a Positive Test Case
Can apply heuristic ‘each valid input at least once in a positive test case’
Consider the following scenario.
SUT: printLabel(fruitName String, unitPrice int)
Selected values for fruitName (invalid values are underlined ):
| Values | Explanation |
|---|---|
| Apple | Label format is round |
| Banana | Label format is oval |
| Cherry | Label format is square |
| Dog | Not a valid fruit |
Selected values for unitPrice:
| Values | Explanation |
|---|---|
| 1 | Only one digit |
| 20 | Two digits |
| 0 | Invalid because 0 is not a valid price |
| -1 | Invalid because negative prices are not allowed |
Suppose these are the test cases being considered.
| Case | fruitName | unitPrice | Expected |
|---|---|---|---|
| 1 | Apple | 1 | Print label |
| 2 | Banana | 20 | Print label |
| 3 | Cherry | 0 | Error message “invalid price” |
| 4 | Dog | -1 | Error message “invalid fruit" |
It looks like the test cases were created using the at least once strategy. After running these tests can we confirm that square-format label printing is done correctly?
- Answer: No.
- Reason:
Cherry-- the only input that can produce a square-format label -- is in a negative test case which produces an error message instead of a label. If there is a bug in the code that prints labels in square-format, these tests cases will not trigger that bug.
In this case a useful heuristic to apply is each valid input must appear at least once in a positive test case. Cherry is a valid test input and we must ensure that it appears at least once in a positive test case. Here are the updated test cases after applying that heuristic.
| Case | fruitName | unitPrice | Expected |
|---|---|---|---|
| 1 | Apple | 1 | Print round label |
| 2 | Banana | 20 | Print oval label |
| 2.1 | Cherry | VV | Print square label |
| 3 | VV | 0 | Error message “invalid price” |
| 4 | Dog | -1 | Error message “invalid fruit" |
VV/IV = Any Invalid or Valid Value VV=Any Valid Value
W11.2d Quality Assurance → Test Case Design → Combining Test Inputs → Heuristic: No More Than One Invalid Input In A Test Case
Can apply heuristic ‘no more than one invalid input in a test case’
Consider the
| Case | fruitName | unitPrice | Expected |
|---|---|---|---|
| 1 | Apple | 1 | Print round label |
| 2 | Banana | 20 | Print oval label |
| 2.1 | Cherry | VV | Print square label |
| 3 | VV | 0 | Error message “invalid price” |
| 4 | Dog | -1 | Error message “invalid fruit" |
VV/IV = Any Invalid or Valid Value VV=Any Valid Value
After running these test cases can you be sure that the error message “invalid price” is shown for negative prices?
- Answer: No.
- Reason:
-1-- the only input that is a negative price -– is in a test case that produces the error message “invalid fruit”.
In this case a useful heuristic to apply is no more than one invalid input in a test case. After applying that, we get the following test cases.
| Case | fruitName | unitPrice | Expected |
|---|---|---|---|
| 1 | Apple | 1 | Print round label |
| 2 | Banana | 20 | Print oval label |
| 2.1 | Cherry | VV | Print square label |
| 3 | VV | 0 | Error message “invalid price” |
| 4 | VV | -1 | Error message “invalid price" |
| 4.1 | Dog | VV | Error message “invalid fruit" |
VV/IV = Any Invalid or Valid Value VV=Any Valid Value
Applying the heuristics covered so far, we can determine the precise number of test cases required to test any given SUT effectively.
False
Explanation: These heuristics are, well, heuristics only. They will help you to make better decisions about test case design. However, they are speculative in nature (especially, when testing in black-box fashion) and cannot give you precise number of test cases.
W11.2e Quality Assurance → Test Case Design → Combining Test Inputs → Mix
Can apply multiple test input combination techniques together
Consider the calculateGrade scenario given below:
- SUT :
calculateGrade(participation, projectGrade, isAbsent, examScore) - Values to test: invalid values are underlined
- participation: 0, 1, 19, 20, 21, 22
- projectGrade: A, B, C, D, F
- isAbsent: true, false
- examScore: 0, 1, 69, 70, 71, 72
To get the first cut of test cases, let’s apply the at least once strategy.
Test cases for calculateGrade V1
| Case No. | participation | projectGrade | isAbsent | examScore | Expected |
|---|---|---|---|---|---|
| 1 | 0 | A | true | 0 | ... |
| 2 | 1 | B | false | 1 | ... |
| 3 | 19 | C | VV/IV | 69 | ... |
| 4 | 20 | D | VV/IV | 70 | ... |
| 5 | 21 | F | VV/IV | 71 | Err Msg |
| 6 | 22 | VV/IV | VV/IV | 72 | Err Msg |
VV/IV = Any Valid or Invalid Value, Err Msg = Error Message
Next, let’s apply the each valid input at least once in a positive test case heuristic. Test case 5 has a valid value for projectGrade=F that doesn't appear in any other positive test case. Let's replace test case 5 with 5.1 and 5.2 to rectify that.
Test cases for calculateGrade V2
| Case No. | participation | projectGrade | isAbsent | examScore | Expected |
|---|---|---|---|---|---|
| 1 | 0 | A | true | 0 | ... |
| 2 | 1 | B | false | 1 | ... |
| 3 | 19 | C | VV | 69 | ... |
| 4 | 20 | D | VV | 70 | ... |
| 5.1 | VV | F | VV | VV | ... |
| 5.2 | 21 | VV/IV | VV/IV | 71 | Err Msg |
| 6 | 22 | VV/IV | VV/IV | 72 | Err Msg |
VV = Any Valid Value VV/IV = Any Valid or Invalid Value
Next, we apply the no more than one invalid input in a test case heuristic. Test cases 5.2 and 6 don't follow that heuristic. Let's rectify the situation as follows:
Test cases for calculateGrade V3
| Case No. | participation | projectGrade | isAbsent | examScore | Expected |
|---|---|---|---|---|---|
| 1 | 0 | A | true | 0 | ... |
| 2 | 1 | B | false | 1 | ... |
| 3 | 19 | C | VV | 69 | ... |
| 4 | 20 | D | VV | 70 | ... |
| 5.1 | VV | F | VV | VV | ... |
| 5.2 | 21 | VV | VV | VV | Err Msg |
| 5.3 | 22 | VV | VV | VV | Err Msg |
| 6.1 | VV | VV | VV | 71 | Err Msg |
| 6.2 | VV | VV | VV | 72 | Err Msg |
Next, let us assume that there is a dependency between the inputs examScore and isAbsent such that an absent student can only have examScore=0. To cater for the hidden invalid case arising from this, we can add a new test case where isAbsent=true and examScore!=0. In addition, test cases 3-6.2 should have isAbsent=false so that the input remains valid.
Test cases for calculateGrade V4
| Case No. | participation | projectGrade | isAbsent | examScore | Expected |
|---|---|---|---|---|---|
| 1 | 0 | A | true | 0 | ... |
| 2 | 1 | B | false | 1 | ... |
| 3 | 19 | C | false | 69 | ... |
| 4 | 20 | D | false | 70 | ... |
| 5.1 | VV | F | false | VV | ... |
| 5.2 | 21 | VV | false | VV | Err Msg |
| 5.3 | 22 | VV | false | VV | Err Msg |
| 6.1 | VV | VV | false | 71 | Err Msg |
| 6.2 | VV | VV | false | 72 | Err Msg |
| 7 | VV | VV | true | !=0 | Err Msg |
Which of these contradict the heuristics recommended when creating test cases with multiple inputs?
(a) inputs.
Explanation: If you test all invalid test inputs together, you will not know if each one of the invalid inputs are handled correctly by the SUT. This is because most SUTs return an error message upon encountering the first invalid input.
Apply heuristics for combining multiple test inputs to improve the E&E of the following test cases, assuming all 6 values in the table need to be tested. underlines indicate invalid values. Point out where the heuristics are contradicted and how to improve the test cases.
SUT: consume(food, drink)
| Test case | food | drink |
|---|---|---|
| TC1 | bread | water |
| TC2 | rice | lava |
| TC3 | rock | acid |
W11.3a Project Management → SDLC Process Models → Introduction → What
Can explain SDLC process models
Software development goes through different stages such as requirements, analysis, design, implementation and testing. These stages are collectively known as the software development life cycle (SDLC). There are several approaches, known as software development life cycle models (also called software process models) that describe different ways to go through the SDLC. Each process model prescribes a "roadmap" for the software developers to manage the development effort. The roadmap describes the aims of the development stage(s), the artifacts or outcome of each stage as well as the workflow i.e. the relationship between stages.
W11.3b Project Management → SDLC Process Models → Introduction → Sequential Models
Can explain sequential process models
The sequential model, also called the waterfall model, models software development as a linear process, in which the project is seen as progressing steadily in one direction through the development stages. The name waterfall stems from how the model is drawn to look like a waterfall (see below).
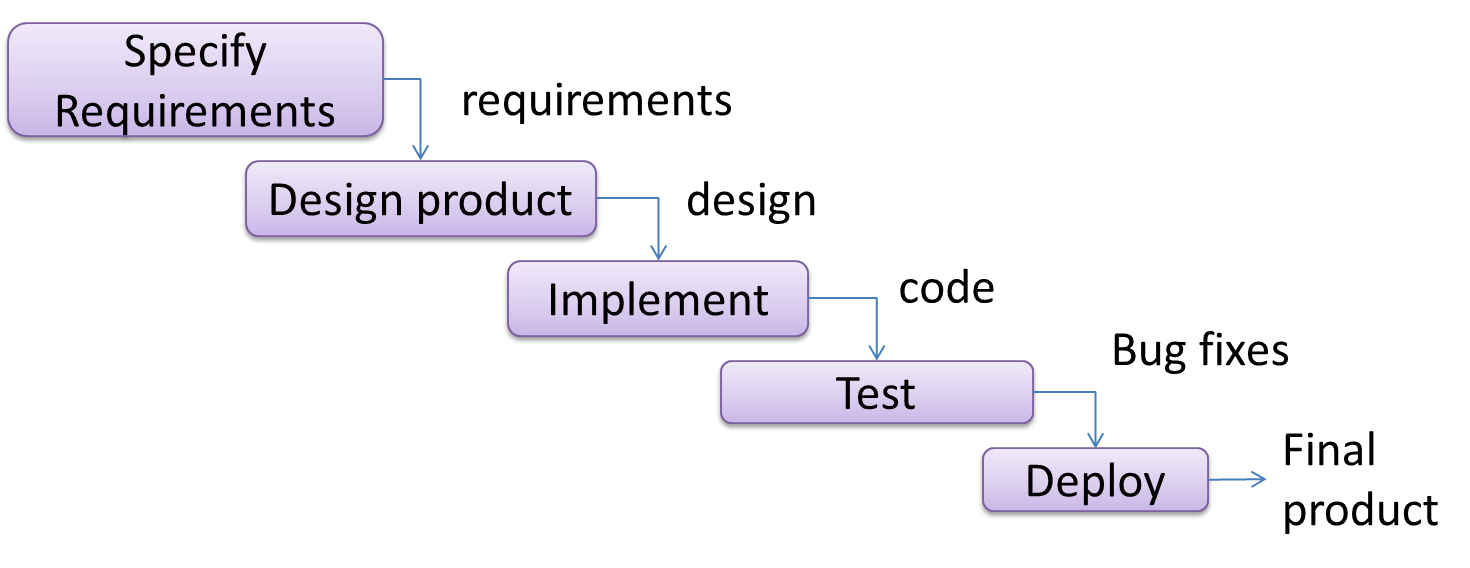
When one stage of the process is completed, it should produce some artifacts to be used in the next stage. For example, upon completion of the requirement stage a comprehensive list of requirements is produced that will see no further modifications. A strict application of the sequential model would require each stage to be completed before starting the next.
This could be a useful model when the problem statement that is well-understood and stable. In such cases, using the sequential model should result in a timely and systematic development effort, provided that all goes well. As each stage has a well-defined outcome, the progress of the project can be tracked with a relative ease.
The major problem with this model is that requirements of a real-world project are rarely well-understood at the beginning and keep changing over time. One reason for this is that users are generally not aware of how a software application can be used without prior experience in using a similar application.
W11.3c Project Management → SDLC Process Models → Introduction → Iterative Models
Can explain iterative process models
The iterative model (sometimes called iterative and incremental) advocates having several iterations of SDLC. Each of the iterations could potentially go through all the development stages, from requirement gathering to testing & deployment. Roughly, it appears to be similar to several cycles of the sequential model.
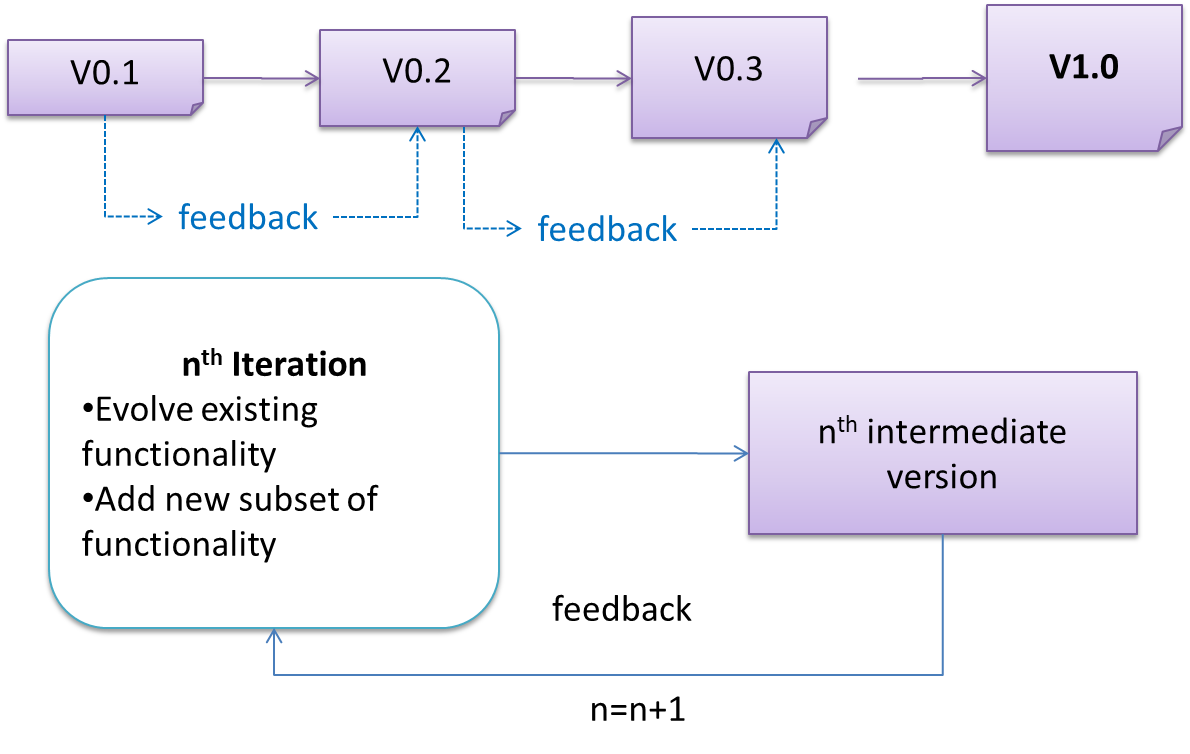
In this model, each of the iterations produces a new version of the product. Feedback on the version can then be fed to the next iteration. Taking the Minesweeper game as an example, the iterative model will deliver a fully playable version from the early iterations. However, the first iteration will have primitive functionality, for example, a clumsy text based UI, fixed board size, limited randomization etc. These functionalities will then be improved in later releases.
The iterative model can take a breadth-first or a depth-first approach to iteration planning.
- breadth-first: an iteration evolves all major components in parallel.
- depth-first: an iteration focuses on fleshing out only some components.
Most project use a mixture of breadth-first and depth-first iterations. Hence, the common phrase ‘an iterative and incremental process’.
W11.3d Project Management → SDLC Process Models → Introduction → Agile Models
Can explain agile process models
In 2001, a group of prominent software engineering practitioners met and brainstormed for an alternative to documentation-driven, heavyweight software development processes that were used in most large projects at the time. This resulted in something called the agile manifesto (a vision statement of what they were looking to do).
We are uncovering better ways of developing software by doing it and helping others do it.
Through this work we have come to value:
- Individuals and interactions over processes and tools
- Working software over comprehensive documentation
- Customer collaboration over contract negotiation
- Responding to change over following a plan
That is, while there is value in the items on the right, we value the items on the left more.
Extract from the Agile Manifesto
Subsequently, some of the signatories of the manifesto went on to create process models that try to follow it. These processes are collectively called agile processes. Some of the key features of agile approaches are:
- Requirements are prioritized based on the needs of the user, are clarified regularly (at times almost on a daily basis) with the entire project team, and are factored into the development schedule as appropriate.
- Instead of doing a very elaborate and detailed design and a project plan for the whole project, the team works based on a rough project plan and a high level design that evolves as the project goes on.
- Strong emphasis on complete transparency and responsibility sharing among the team members. The team is responsible together for the delivery of the product. Team members are accountable, and regularly and openly share progress with each other and with the user.
There are a number of agile processes in the development world today. eXtreme Programming (XP) and Scrum are two of the well-known ones.
Choose the correct statements about agile processes.
- a. They value working software over comprehensive documentation.
- b. They value responding to change over following a plan.
- c. They may not be suitable for some type of projects.
- d. XP and Scrum are agile processes.
(a)(b)(c)(d)
W11.3e Project Management → SDLC Process Models → Scrum
Can explain scrum
This description of Scrum was adapted from Wikipedia [retrieved on 18/10/2011], emphasis added:
Scrum is a process skeleton that contains sets of practices and predefined roles. The main roles in Scrum are:
- The Scrum Master, who maintains the processes (typically in lieu of a project manager)
- The Product Owner, who represents the stakeholders and the business
- The Team, a cross-functional group who do the actual analysis, design, implementation, testing, etc.
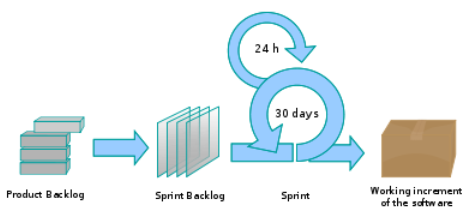
A Scrum project is divided into iterations called Sprints. A sprint is the basic unit of development in Scrum. Sprints tend to last between one week and one month, and are a timeboxed (i.e. restricted to a specific duration) effort of a constant length.
Each sprint is preceded by a planning meeting, where the tasks for the sprint are identified and an estimated commitment for the sprint goal is made, and followed by a review or retrospective meeting, where the progress is reviewed and lessons for the next sprint are identified.
During each sprint, the team creates a potentially deliverable product increment (for example, working and tested software). The set of features that go into a sprint come from the product backlog, which is a prioritized set of high level requirements of work to be done. Which backlog items go into the sprint is determined during the sprint planning meeting. During this meeting, the Product Owner informs the team of the items in the product backlog that he or she wants completed. The team then determines how much of this they can commit to complete during the next sprint, and records this in the sprint backlog. During a sprint, no one is allowed to change the sprint backlog, which means that the requirements are frozen for that sprint. Development is timeboxed such that the sprint must end on time; if requirements are not completed for any reason they are left out and returned to the product backlog. After a sprint is completed, the team demonstrates the use of the software.
Scrum enables the creation of self-organizing teams by encouraging co-location of all team members, and verbal communication between all team members and disciplines in the project.
A key principle of Scrum is its recognition that during a project the customers can change their minds about what they want and need (often called requirements churn), and that unpredicted challenges cannot be easily addressed in a traditional predictive or planned manner. As such, Scrum adopts an empirical approach—accepting that the problem cannot be fully understood or defined, focusing instead on maximizing the team’s ability to deliver quickly and respond to emerging requirements.
Daily Scrum is another key scrum practice. The description below was adapted from https://www.mountaingoatsoftware.com (emphasis added):
In Scrum, on each day of a sprint, the team holds a daily scrum meeting called the "daily scrum.” Meetings are typically held in the same location and at the same time each day. Ideally, a daily scrum meeting is held in the morning, as it helps set the context for the coming day's work. These scrum meetings are strictly time-boxed to 15 minutes. This keeps the discussion brisk but relevant.
...
During the daily scrum, each team member answers the following three questions:
- What did you do yesterday?
- What will you do today?
- Are there any impediments in your way?
...
The daily scrum meeting is not used as a problem-solving or issue resolution meeting. Issues that are raised are taken offline and usually dealt with by the relevant subgroup immediately after the meeting.
(This is not an endorsement of the product mentioned in the video)
W11.3f Project Management → SDLC Process Models → XP
Can explain XP
The following description was adapted from the XP home page, emphasis added:
Extreme Programming (XP) stresses customer satisfaction. Instead of delivering everything you could possibly want on some date far in the future, this process delivers the software you need as you need it.
XP aims to empower developers to confidently respond to changing customer requirements, even late in the life cycle.
XP emphasizes teamwork. Managers, customers, and developers are all equal partners in a collaborative team. XP implements a simple, yet effective environment enabling teams to become highly productive. The team self-organizes around the problem to solve it as efficiently as possible.
XP aims to improve a software project in five essential ways: communication, simplicity, feedback, respect, and courage. Extreme Programmers constantly communicate with their customers and fellow programmers. They keep their design simple and clean. They get feedback by testing their software starting on day one. Every small success deepens their respect for the unique contributions of each and every team member. With this foundation, Extreme Programmers are able to courageously respond to changing requirements and technology.
XP has a set of simple rules. XP is a lot like a jig saw puzzle with many small pieces. Individually the pieces make no sense, but when combined together a complete picture can be seen. This flow chart shows how Extreme Programming's rules work together.
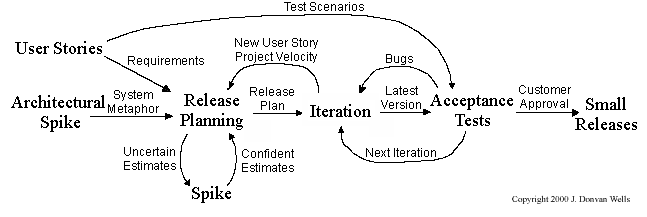
Pair programming, CRC cards, project velocity, and standup meetings are some interesting topics related to XP. Refer to extremeprogramming.org to find out more about XP.
W11.3g Project Management → SDLC Process Models → Unified Process
Can explain the Unified Process
The unified process is developed by the Three Amigos - Ivar Jacobson, Grady Booch and James Rumbaugh (the creators of UML).
The unified process consists of four phases: inception, elaboration, construction and transition. The main purpose of each phase can be summarized as follows:
| Phase | Activities | Typical Artifacts |
|---|---|---|
| Inception |
|
|
| Elaboration |
|
|
| Construction |
|
|
| Transition |
|
|

Given above is a visualization of a project done using the Unified process (source: Wikipedia). As the diagram shows, a phase can consist of several iterations. Each vertical column (labeled “I1” “E1”, “E2”, “C1”, etc.) represents a single iteration. Each of the iterations consists of a set of ‘workflows’ such as ‘Business modeling’, ‘Requirements’, ‘Analysis & Design’ etc. The shaded region indicates the amount of resource and effort spent on a particular workflow in a particular iteration.
Unified process is a flexible and customizable process model framework rather than a single fixed process. For example, the number of iterations in each phase, definition of workflows, and the intensity of a given workflow in a given iteration can be adjusted according to the nature of the project. Take the Construction Phase, to develop a simple system, one or two iterations would be sufficient. For a more complicated system, multiple iterations will be more helpful. Therefore, the diagram above simply records a particular application of the UP rather than prescribe how the UP is to be applied. However, this record can be refined and reused for similar future projects.
Choose the correct statements about the unified process.
- a. It was conceived by the three amigos who also created UML.
- b. The Unified process requires the use of UML.
- c. The Unified process is actually a process framework rather than a fixed process.
- d. The Unified process can be iterative and incremental
(a)(b)(c)(d)
Explanation: Although UP was created by the same three amigos who created UML, the UP does not require UML.
W11.3h Project Management → SDLC Process Models → CMMI
Can explain CMMI
CMMI (Capability Maturity Model Integration) is a process improvement approach defined by Software Engineering Institute at Carnegie Melon University. CMMI provides organizations with the essential elements of effective processes, which will improve their performance. -- adapted from http://www.sei.cmu.edu/cmmi/
CMMI defines five maturity levels for a process and provides criteria to determine if the process of an organization is at a certain maturity level. The diagram below [taken from Wikipedia] gives an overview of the five levels.

W11.3i Project Management → SDLC Process Models → Recap
Can explain process models at a higher level
This section has some exercise that cover multiple topics related to SDLC process models.
Discuss how sequential approach and the iterative approach can affect the following aspects of a project.
a) Quality of the final product.
b) Risk of overshooting the deadline.
c) Total project cost.
d) Customer satisfaction.
e) Monitoring the project progress.
f) Suitability for a school project
a) Quality of the final product:
- Iterative: Frequent reworking can deteriorate the design. Frequent refactoring should be used to prevent this. Frequent customer feedback can help to improve the quality (i.e. quality as seen by the customer).
- Sequential: Final quality depends on the quality of each phase. Any quality problem in any phase could result in a low quality product.
b) Risk of overshooting the deadline.
- Iterative: Less risk. If the last iteration got delayed, we can always deliver the previous version. However, this does not guarantee that all features promised at the beginning will be delivered on the deadline.
- Sequential: High risk. Any delay in any phase can result in overshooting the deadline with nothing to deliver.
c) Total project cost.
- Iterative: We can always stop before the project budget is exceeded. However, this does not guarantee that all features promised at the beginning will be delivered under the estimated cost. (The sequential model requires us to carry on even if the budget is exceeded because there is no intermediate version to fall back on).
Iterative reworking of existing artifacts could add to the cost. However, this is “cheaper” than finding at the end that we built the wrong product.
d) Customer satisfaction
- Iterative: Customer gets many opportunities to guide the product in the direction he wants. Customer gets to change requirements even in the middle of the product. Both these can increase the probability of customer satisfaction.
- Sequential: Customer satisfaction is guaranteed only if the product was delivered as promised and if the initial requirements proved to be accurate. However, the customer is not required to do the extra work of giving frequent feedback during the project.
e) Monitoring project progress
- Iterative: Hard to measure progress against a plan, as the plan itself keeps changing.
- Sequential: Easier to measure progress against the plan, although this does not ensure eventual success.
f) Suitability for a school project:
Reasons to use iterative:
- Requirements are not fixed.
- Overshooting the deadline is not an option.
- Gives a chance to learn lessons from one iteration and apply them in the next.
Sequential:
- Can save time because we minimize rework.
Find out more about the following three topics and give at least three arguments for and three arguments against each.
(a) Agile processes
(b) Pair programming
(c) Test-driven development
(a) Arguments in favor of agile processes:
- More focus on customer satisfaction.
- Less chance of building the wrong product (because of frequent customer feedback).
- Less resource wasted on bureaucracy, over-documenting, contract negotiations.
Arguments against agile processes (not necessarily true):
- It is ‘just hacking’. Not very systematic. No discipline.
- It is hard to know in advance the exact final product.
- It does not give enough attention to documentation.
- Lack of management control (gives too much freedom to developers)
(b) Arguments in favor of pair programming:
- It could produce better quality code.
- It is good to have more than one person know about any piece of code.
- It is a way to learn from each other.
- It can be used to train new programmers.
- Better discipline and better time management (e.g. less likely to play Farmville while working).
- Better morale due to more interactions with co-workers.
Arguments against pair programming:
- Increase in total man hours required
- Personality clashes between pair-members
- Workspaces need to be adapted to suit two developers working at one computer.
- If pairs are rotated, one needs to know more parts of the system than in solo programming
(c) Arguments in favor of TDD:
- Testing will not be neglected due to time pressure (because it is done first).
- Forces the developer to think about what the component should be before jumping into implementing it.
- Optimizes programmer effort (i.e. if all tests pass, there is no need to add any more functionality).
- Forces us to automate all tests.
Arguments against TDD (not necessarily true):
- Since tests can be seen as ‘executable specifications’, programmers tend to neglect others forms of documentation.
- Promotes ‘trial-and-error’ coding instead of making programmers think through their algorithms (i.e. ‘just keep hacking until all tests pass’).
- Gives a false sense of security. (what if you forgot to test certain scenarios?)
Not intuitive. Some programmer might resist adopting TDD.
The sequential model and the waterfall model are the two most basic process models.
False
Explanation: The sequential model and the waterfall model are the same thing. The second basic model is the iterative model.
Choose the correct statements about the sequential and iterative process models.
- a. The sequential model organizes the project based on activities.
- b. The iterative and incremental model organizes the project based on functionality.
- c. The iterative model can be breadth-first or depth-first.
- d. The iterative model is always better than the sequential model.
- e. Compared to the sequential model, the iterative model is better at adapting to changing requirements.
(a)(b)(c)(d)(e)
Explanation: Both models have pros and cons. There is no definitive ‘better’ choice between the two. However, the iterative model works better in typical software projects than a purely sequential approach.
In general, which has a higher risk of overshooting a deadline?
(b)
Explanation: An iterative process can meet a deadline better than a sequential process. If the last iteration got delayed, we can always deliver the previous version. However, this does not guarantee that all features promised at the beginning will be delivered on the deadline.