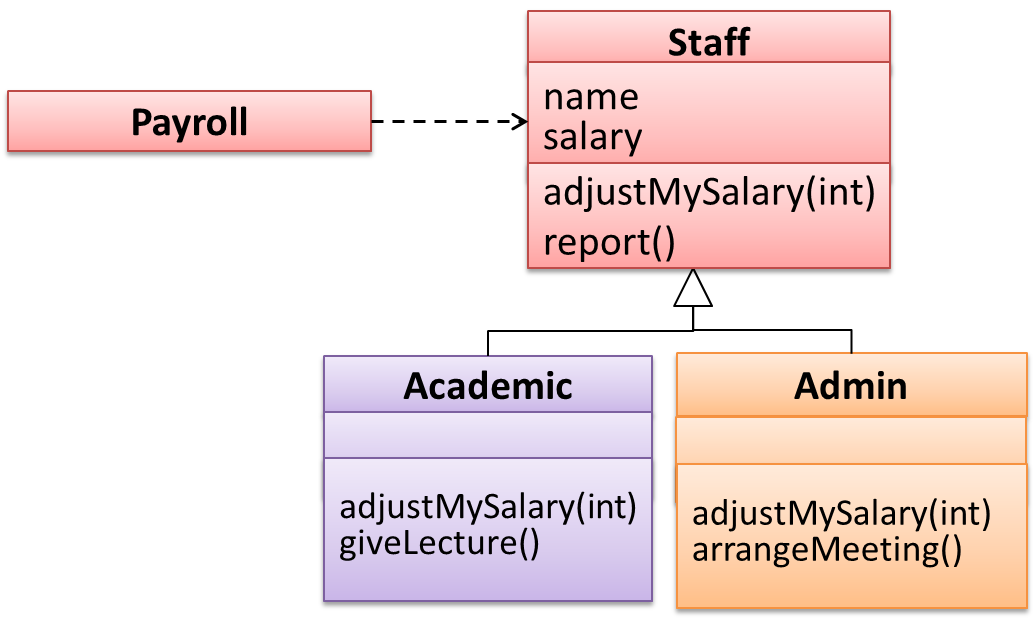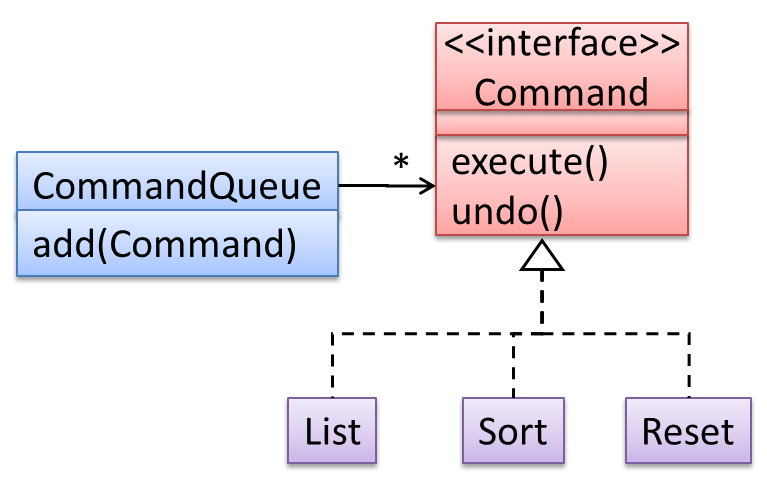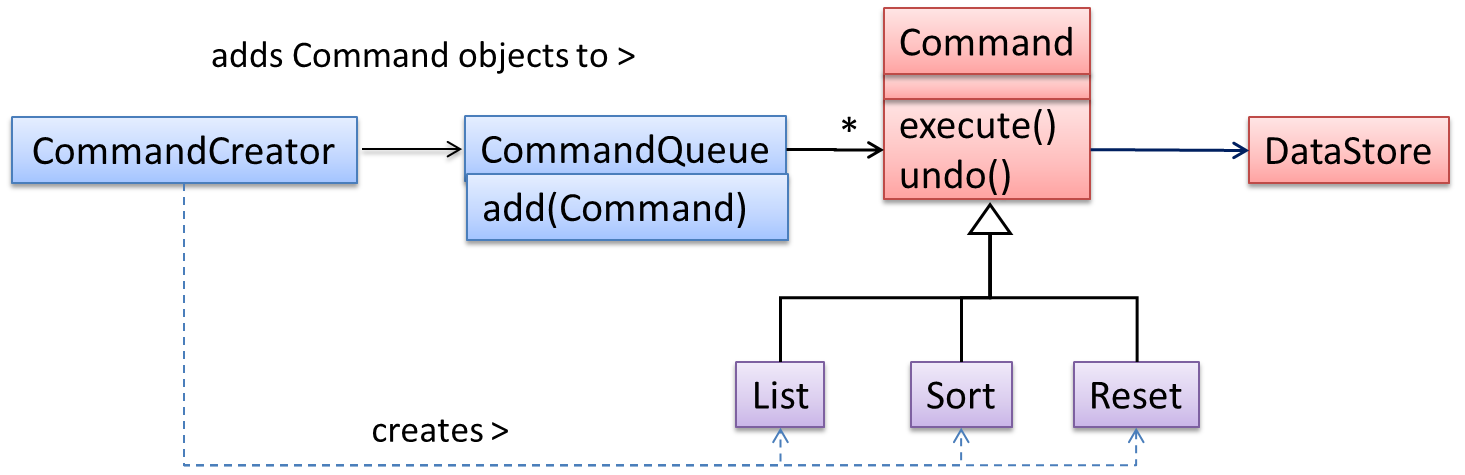
Method overriding is when a sub-class changes the behavior inherited from the parent class by re-implementing the method. Overridden methods have the same name, same type signature, and same return type.
Consider the following case of EvaluationReport class inheriting the Report class:
Report methods |
EvaluationReport methods |
Overrides? |
|---|---|---|
print() |
print() |
Yes |
write(String) |
write(String) |
Yes |
read():String |
read(int):String |
No. Reason: the two methods have different signatures; This is a case of |
Paradigms → OOP → Inheritance →
Method overloading is when there are multiple methods with the same name but different type signatures. Overloading is used to indicate that multiple operations do similar things but take different parameters.
Type Signature: The type signature of an operation is the type sequence of the parameters. The return type and parameter names are not part of the type signature. However, the parameter order is significant.
Example:
| Method | Type Signature |
|---|---|
int add(int X, int Y) |
(int, int) |
void add(int A, int B) |
(int, int) |
void m(int X, double Y) |
(int, double) |
void m(double X, int Y) |
(double, int) |
In the case below, the calculate method is overloaded because the two methods have the same name but different type signatures (String) and (int)
calculate(String): voidcalculate(int): void
Which of these methods override another method? A is the parent class. B inherits A.
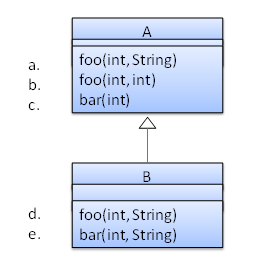
- a
- b
- c
- d
- e
d
Explanation: Method overriding requires a method in a child class to use the same method name and same parameter sequence used by one of its ancestors